See RPE PUB’s True Colors
In this IBM Engineering Tool Tip, IBM Champion Kevin Murphy shows how turning on a pretty buried feature in the Publishing Engine Eclipse Client can help make template development much easier.
In this IBM Engineering Tool Tip, IBM Champion Kevin Murphy shows how turning on a pretty buried feature in the Publishing Engine Eclipse Client can help make template development much easier.
In this IBM Engineering Tool Tip, Kevin explains Why Your DOORS Next Report Builder results have duplicate entries and how to fix them!
IBM released Engineering Lifecycle Management 7.0 for general release today, and while we’ve covered Requirements Management with DOORS Next in some detail, we wanted to also cover highlights of the rest of the suite.
All of the applications have had their names changed, for better or for worse. I think some of these are going to have a hard time sticking. That said, here are the new names across the board:
| Old Name | Old Acronym | New Name | New Acronymn |
| Rational or Collaborative Lifecycle Management or Continuous Engineering | CLM or CE | IBM Engineering Lifecycle Management | ELM |
| Rational DOORS | DOORS | DOORS Family | DOORS |
| Rational DOORS Next Generation | DNG | DOORS Next | DOORS Next |
| Rational Rhapsody | — | Rhapsody | — |
| Rational Rhapsody Design Manager | RDM | Rhapsody – Design Manger | RDM |
| Rational Rhapsody Model Manager | RMM | Rhapsody – Model Manager | RDM |
| Rational Quality Manager | RQM | Engineering Test Management | ETM |
| Rational Team Concert | RTC | Engineering Workflow Management | EWM |
| Rational Publishing Engine | RPE | Publishing | PUB |
| Rational Engineering Lifecycle Manager | RELM | Engineering Insights | ENI |
| Rational Method Composer | — | Method Composer | MEC |
The above is not the official IBM names to a T–I’ve slightly abbreviated some things. Keep that in mind.
The product banner looks much more modern.

In theory this will improve performance. Please contact us or leave a comment below if you’re using this feature.
500 adapters running in parallel are supported! Pretty huge improvement there.
I actually developed a workaround for not having this years ago. It’s finally in the tool, fully supported!
You can ignore individual resources when LQE fails on a given artifact. Again, big improvement here.

I’ve never had a client ask for this, but I’m glad this is there.
This is interesting and I am not sure of why you would want to do this, but you can duplicate an active change set in Eclipse and Visual Studio.
The program board in particular looks fantastic! Of note, color tags are supported as well.
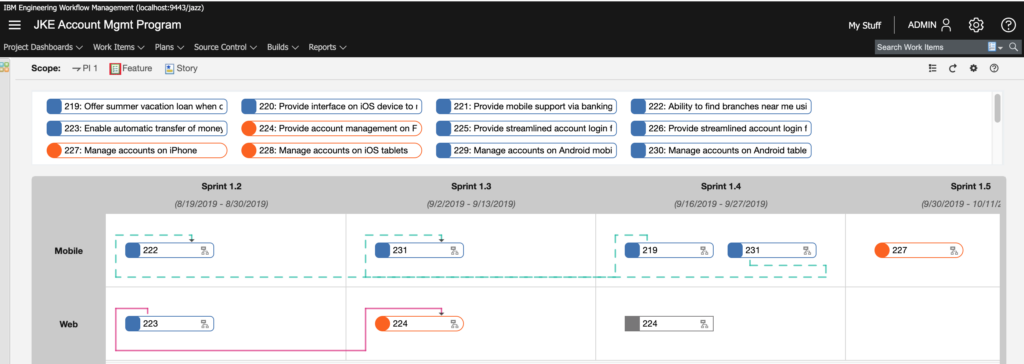
Unfortunately, there’s not much to report here as far as our interests. The improvements appear to have all gone to Document Builder and not to the Publishing thick client.
As an aside, it’s going to be very difficult for me to call it just “Publishing.” Really wish Publishing Engine had stuck instead.
Previously, a report author could only create a custom column with a calculation on a single attribute. For instance, it was not possible to calculate a RPN for an FMEA-style report by creating a custom column that inspected both Likelihood and Occurence. You could only make a column that say, truncated Likelihood and that’s it. This was a *severe* limitation.
Enter version 7.0!
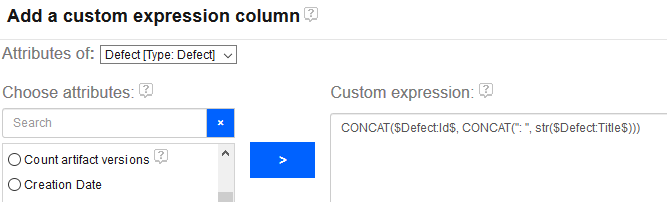
We are pleased to announce the release of our latest utility: The DSX Files. This utility will help report authors/developers who use IBM ENI Publishing (aka Rational Publishing Engine) to develop document export templates against IBM DOORS Next.
Please read more about its features here.
Just wanted to give a heads up that IBM CLM 6.0.4 was released yesterday on jazz.net. Keep watching this space for details of new features.
Just wanted to give everyone a heads up that Rational Publishing Engine (RPE) 2.1 is now available. Per RPEActual:
I’m happy to announce RPE 2.1, codename Multumesc, has been made generally available today. With this release we continued on the path we started in RPE 2.0 around simplifying the user experience with RPE. While with 2.0 and 2.0.1 we focused on administrators and end users with 2.1 our focus are template designers:
* Interactive Guides – new designers will be walked through the design process
* Drag&Drop for quick template design– drop your resource URL from the Browser in document studio and RPE will create a starting template for you
* Simplified CLM tracebality – with the POX profile you no longer need to manipulate URLs to transform between OSLC and REST API.
* Word Import – use Word documents as the starting point of your template. RPE will convert the structure and a subset of the formatting into an RPE template
* Java Script Reuse – you can now define code modules inside a template and reuse the functions defined there everywhere else in the template.
That all sounds AWESOME to me! Looking forward to trying this all out as soon as I can.
The RPE team also posted Youtube videos.
https://www.youtube.com/playlist?list=PLZGO0qYNSD4UtXl3xXGsL1hhumg0s8m9i
RPE 1.3 was recently released and the very first thing I encountered with it was that you can no longer generate DOORS Next Generation documents from a DNG-generated document specification (.dsx) file in the RPE Launcher.
If you don’t know what I’m talking about, this article on Dragos’ RPE Actual should clear it up. This technique will no longer work with RPE 1.3 due to the “cookies” section of the .dsx file not being available.
IBM can provide you with a fix. So open up those PMRs, folks. There’s also a related issue with how oAuth is misbehaving for DNG in RPE 1.3, so hopefully IBM will have a patch for these issues shortly.
One of the coolest pieces of DOORS-related tech I saw at Innovate 2014 was Author XG by GEBS. GEBS developed the early versions of Rational Publishing Engine and really know their stuff when it comes to Document Generation and Reporting via DOORS. Author XG is basically RPE for non-technical people. Awesome stuff.
If you want to see Author XG and even learn more about RPE, GEBS is hosting a few FREE webinars over the coming months.
The first Webinar is Tuesday July 29th 2014
9:00 AM NA Eastern Time (UTC – 4)
9:00 AM NA Pacific Time (UTC – 7)
Do you want to know more about document generation? Are you curious to learn how automated publishing might benefit your organization? Then why not join us for our introductory tour of document generation technologies and discover the tools, methods and solutions that can enhance both your bottom line and delivery capability. (Note – this introductory webinar is industry/tool agnostic, and not specific to IBM Rational Publishing Engine).
The webinar will last approximately 1 hour with a question and answer session. Registration and attendance is free.
Presenter: Alex Feseto of GEBS
This is the first webinar in an enlightenment series on document generation, below you can find the schedule for the next episodes:
Tuesday August 12th – Getting Started With Rational Publishing Engine – Register now
Thursday September 4th – Introducing Author XG: the future of document generation
September TBA – Introducing Reporting Central: the modular CMS for RPE and Author XG
October TBA – Advanced hints, tips & tricks for RPE and friends
October TBA – End to end document generation with RPE, Author XG, Reporting Central and Web Publisher
October TBA – Generating documents across the SDLC
Head to the 4.0.6 downloads page and grab the latest release.
When CLM 4.0.5 was released I listed all of the enhancements in one page. This new release (which includes Rational Jazz Foundation, Rational DOORS Next Generation, Rational Team Concert, and Rational Quality Manager) appears to address bug fixes and does not appear to add new features.
I’ll update this post as I learn more.
I wonder if my last post had anything to do with this.
How to remove “Table” caption prior extracting document in IBM Rational Publishing Engine
What a horrible title for this technote. The “Table” caption comes in as a HEADING, not a caption. And this problem only exists in exports from DOORS that were brought in from MS Word and that is also not mentioned. The word DOORS isn’t even in the title, which tells me that most RPE customers are using DOORS.
While the information in the technote is valuable, I still can find no actual reason any long time user of DOORS would want invisible table headers to have a heading of “Table” on tables exported to DOORS from Word documents. Unless every DOORS table will always have this heading regardless of where it is created, this “feature” needs to be removed in the next release.
